- Harnessing Administrative Data Inventories to Create a Reliable Transnational Reference Database for Crop Type Monitoring. IEEE International Geoscience and Remote Sensing Symposium (IGARSS), IEEE, 2022 more… Full text ( DOI )
Knowledge Distillation from Big Administrative Data (KnowDisBAD)
A Linde/MDSI PhD Fellowship Project
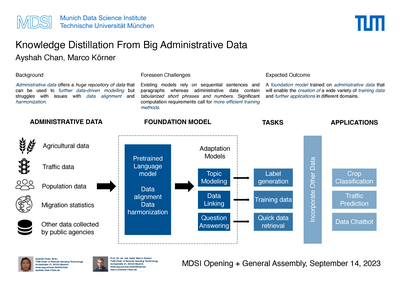
Data-driven modeling through deep learning techniques has shown tremendous success in the past years in various research domains. However, these exhibit significant practical shortcomings, not least their need for large amounts of high-quality data annotations to train such models. Usually, such data is notoriously
scarce and expensive to be mined, limiting the translation of machine learning concepts to application domains that seek to benefit from them.
On the other hand, there are huge repositories that get acquired by administrative and governmental bodies for the sake of enabling public services and processes. Such administrative data or government data can be assumed to be acquired according to high quality standards and in a timely manner. They are usually organized in tabular form, which is conducive to automated processing. Nevertheless, administrative bodies do not usually follow agreed protocols, making these fragmented data stocks hard to align.
Using the example of farmers’ self-declarations in the context of the allocations of agricultural subsidies, the EuroCrops project at the Chair of Remote Sensing Technology seeks to harmonize such data sources and demonstrate its potential. It turns out that the design of such harmonization schemes require a significant amount of domain knowledge and many iterations to improve. Evidently, such competencies and resources are often not available, particularly in a formalized manner. However, each EuroCrops dataset element, i.e., the individual parcel polygons, is associated with uniquely referenced geo-coordinates that may be used as key identifiers. Automated methods for data alignment and harmonization are therefore needed, and recent developments from the machine learning research community, particularly in the field of natural language processing (NLP), can obviously be helpful for this purpose. Not least, recent large language models (LLMs), like the series of generative Pre-trained Transformer (GPT) models and applications derived from them, such as ChatGPT, succeed in extracting information from huge and diverse data sources and aggregating it thematically.
Concomitantly, such systems face problems as they risk providing false or misleading information comprehension while appearing overly confident, caused by the uneven and biased distribution of training data and the sheer complexity of the trained models. Therefore, such data aggregation and processing regimes must meet fairness and privacy standards, while explainability and transparency of the trained models need to be ensured.
This project aims to address the above challenges and find answers to the following research questions:
- Can the tedious process of data harmonization be automated and how does this compare to manually designed harmonizing schemes, e.g., the hierarchical crop and agriculture taxonomy (HCAT) from EuroCrops?
- Can relevant information be identified in harmonized datasets or directly from the raw data sources?
- Can these processes be adapted over time and as new data sources are to be considered?
- How can privacy and fairness concerns be addressed throughout the entire workflow?