- Harnessing Administrative Data Inventories to Create a Reliable Transnational Reference Database for Crop Type Monitoring. IEEE International Geoscience and Remote Sensing Symposium (IGARSS), IEEE, 2022 mehr… Volltext ( DOI )
Wissensdestillation aus großen Verwaltungsdaten (KnowDisBAD)
Linde/MDSI Doctoral Fellowship
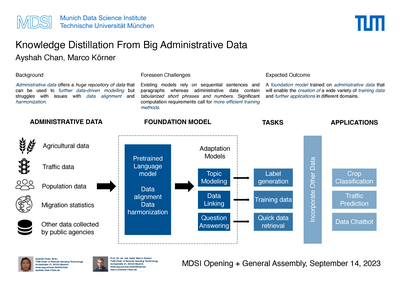
Die auf Deep-Learning-Techniken basierende datentriebene Modellierung hat in den letzten Jahren ernorme Erfolge in verschiedenen Forschungsbereichen gezeigt. Diese Verfahren weisen jedoch erhebliche praktische Mängel auf, nicht zuletzt begründet durch der Notwendigkeit an große Mengen an hochwertigen Datenannotationen zum Trainieren solche Modelle. Üblicherweise sind solche Daten knapp und teuer, was die Übertragung von Konzepten des maschinellen Lernens auf Anwendungsbereiche, die von ihnen profitieren wollen, enorm einschränkt.
Auf der anderen Seite existieren riesige Datenbestände, die regelmäßig von Verwaltungs- und Regierungsstellen erworben werden, um öffentliche Dienstleistungen und Prozesse zu ermöglichen. Es kann davon ausgegangen werden, dass solche Verwaltungs- oder Regierungsdaten nach hohen Qualitätsstandards und zeitnah erfasst werden. Sie liegen in der Regel in tabellarischer Form organisiert vor, was einer automatisierten Verarbeitung förderlich ist. Dennoch existieren kaum vereinbarte Standard zur Erhebung, Speicherung unv Verarbeitung solcher Daten, so dass diese fragmentierten Datenbestände nur schwer miteinander in Einklang zu bringen sind.
Das Projekt EuroCrops am Lehrstuhl für Methodik der Fernerkundung versucht am Beispiel der im Zusammenhang mit der Vergabe von Agrarsubventionen anfallenden Selbstdeklarationen der Landwirte, solche Datenquellen zu harmonisieren und deren Potenzial aufzuzeigen. Es hat sich herausgestellt, dass die Entwicklung solcher Harmonisierungssysteme ein erhebliches Maß an Fachwissen und viele Iterationen zur Verbesserung erfordert. Offensichtlich sind solche Kompetenzen und Ressourcen oft nicht verfügbar, insbesondere nicht in formalisierter Form. Jedes Element des EuroCrops-Datensatzes, d. h. jedes einzelne Parzellenpolygon, ist jedoch mit eindeutig referenzierten Geokoordinaten verbunden, die als Schlüsselidentifikatoren verwendet werden können. Daher sind automatisierte Methoden für den Datenabgleich und die Harmonisierung erforderlich. Die jüngsten Entwicklungen in der Forschung im Bereich des maschinellen Lernens, insbesondere im Bereich der Verarbeitung natürlicher Sprache, können für diesen Zweck offensichtlich hilfreich sein. Nicht zuletzt gelingt es neueren großen Sprachmodellen (LLMs), wie den generativen pre-trained transformer (GPT)-Modellen und daraus abgeleiteten Anwendungen wie ChatGPT, Informationen aus riesigen und vielfältigen Datenquellen zu extrahieren und zu aggregieren. und vielfältigen Datenquellen zu extrahieren und thematisch zu aggregieren.
Dieses Projekt soll sich den genannten Herausforderungen stellen und Antworten auf folgende Forschungsfragen finden:
- Kann der langwierige Prozess der Datenharmonisierung automatisiert werden? Wie verhält sich dies im Vergleich zu manuell erstellten Harmonisierungsschemata, z. B. der im Rahmen von EuroCrops entwickelten hierarchischen Taxonomie für Kulturpflanzen und Landwirtschaft (HCAT)?
- Können relevante Informationen in harmonisierten Datensätzen oder direkt in den Rohdatenquellen identifiziert werden?
- Können diese Prozesse im Laufe der Zeit angepasst werden, wenn neue Datenquellen berücksichtigt werden sollen?
- Wie können die Belange des Datenschutzes und der Fairness während des gesamten Arbeitsablaufs berücksichtigt werden?